The Productivity Burden of Monitoring and Observability — And What Comes Next

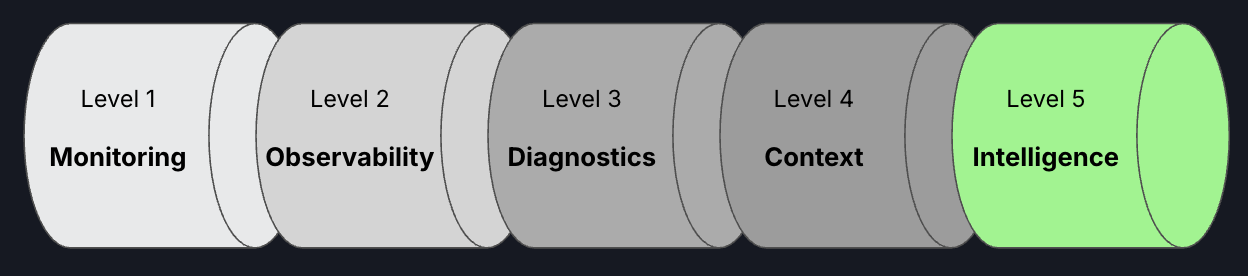
Despite having more data than ever, most software engineering orgs are stuck with tooling at Level 1–2 on the reliability capability scale. As a result engineers are saddled with manual work investigating errors, alerts and incidents.
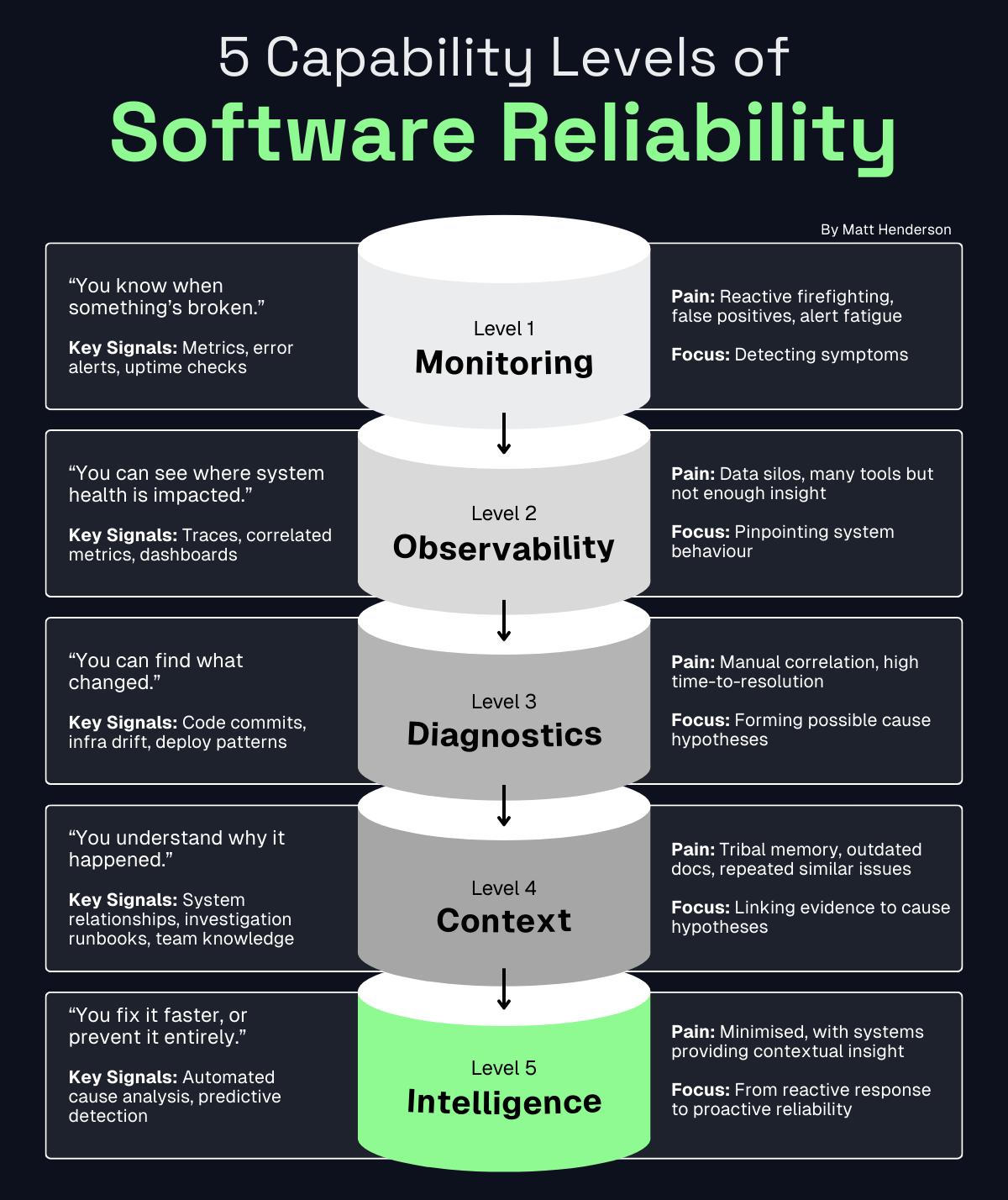
At Level 1, monitoring tells you when something has broken. At Level 2, observability helps you pinpoint where it’s happening. Both are essential, but neither tells you why it happened, how to fix it, or how to prevent it from happening again.
The Hidden Cost of Level 1–2 Tooling
Most engineering teams quietly absorb the limitations of the first two capability levels. They accept the manual toil between “an alert fired” and “we understand what to do and why.” But that gap is expensive — in time, in focus, and in lost engineering velocity.
Here are the signs a team is stuck in Level 1–2 reliability:
- Alerts and customer escalations constantly interrupt feature work, pulling engineers into reactive firefighting.
- Incident investigation depends heavily on tribal knowledge — usually from the few people who understand that corner of the system well enough to trace the failure.
- High alert volume, but customers are still the first to notice key issues, signalling that the tooling isn’t providing meaningful insight.
Traditional monitoring and observability surface signals, but they don’t connect them. They also miss critical understanding of other data sources, in particular code. This leaves signal interpretation to humans, and as systems grow more complex, that manual work becomes a larger and larger burden.
The Next Capability Levels: From Understanding Symptoms to Understanding Causes.
Levels 3, 4, and 5 on the reliability capability scale introduces something new: reasoning.
- Diagnostics (Level 3): You can identify what changed (code commits, configuration drift, deploy patterns).
- Context (Level 4): You can link evidence together to understand why the issue occurred.
- Intelligence (Level 5): Systems can surface causes automatically and even predict issues before they impact customers.
At Level 5, the goal isn’t just to reduce MTTR, it’s to dramatically reduce the number of incidents that reach production in the first place.
This future isn’t about more dashboards. It’s about fewer pages, less manual troubleshooting, and a system that understands your architecture well enough to reason about what has — and will — happen.
The Future We’re Building at Phoebe
The gaps between Level 2 and Level 5 are currently filled by human effort: digging through logs, correlating metrics, interviewing teammates, reconstructing timelines, and forming hypotheses under pressure. Phoebe assists and automates that manual work with a system that builds understanding of your architecture and automatically connects the dots.
Because reliability shouldn’t depend on the one person who remembers how that service behaves on a Tuesday. The future of software reliability is intelligent, contextual, and proactive.
And that’s Level 5.